| Section |
|---|
Its a sad fact of life but Tableauwillprobablynotwon't be around foreverCertainly as your company seeks out newer tools and data continues to grow exponentiallyThe problem is, your company knows this and has built, and continues to build systems in order to progress |
...
| Expand | ||||||||
|---|---|---|---|---|---|---|---|---|
| ||||||||
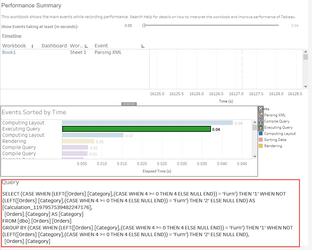
... you will need to create calculations in order for you to provide your analyses however, there are right ways and wrong ways to create calculations with the wrong ways having a detrimental effect to the back-end; however, only through the of the performance recorder will you know for sure the true impacts that you calculations are having. Classically, consider this calculation:
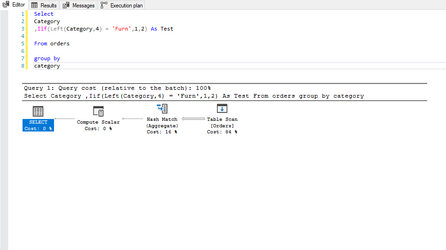
This is the query and execution plan from SQL Server:
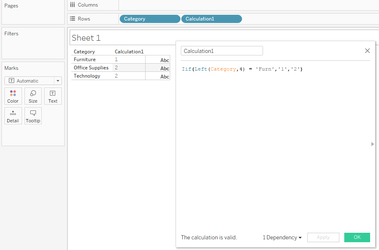
And now in Tableau:
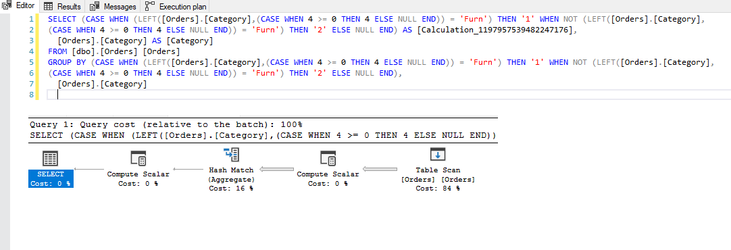
Notice the additional operation in the plan? In this instance, this has resulted in a minimal change on a 9994 row set, but can you imagine the impact this could have on a million / billion or even trillion row set? Moreover, this example uses a table with no performance enhancements which has resulted in a full table scan and hash-match in both queries but crucially, if the table was indexed, the first query would likely be able to use the index to reduce the number of rows to be processed whereas the resultant query Tableau has produced, would mean the index would discarded and a full table scan would be required. Moral of the story, yes, calculations are needed, you will be lost without them, but, just ensure the calculations you write perform to their best with minimal impact eg:
|
...
| Expand | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||
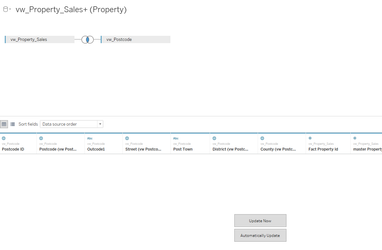
... that you will benefit from the best experience. See my article About: Custom SQL an in-depth explanation but CustomSQL offers the best performance: As an SQL analyst, you have the tools to be able to write much more performant code, and to test this code and where necessary, gain advice from others about how best to tune the query whereas, simply dragging and dropping the table objects and relying on Tableau to process the fields and connections, means that no-one will be able to optimise the code. Also, most BI teams make data available through the use of optimised view's rather than direct access to the table so when Tableau executes its connection such as:
The query that Tableau is sending to the database engine will be a variation of:
this view for example:
will generate a query similar to:
But, where view's are used as is the case here, the actual query that needs to be processed by the database engine will actually look more like:
Which you can see is functionally identical to oft quoted reasons for NOT using CustomSQL. However, two major points not covered which are generally the most important reasons for using CustomSQL:
In short, CustomSQL allows you to harness the best from your database with the least amount of impact and to be able better control you data |
...
| Expand | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||
... consider this calculation to alter the alias of Tenure Type : (running over a 30M row optimised set:
Where aliases, being a Tableau object result in no execution time in order to generate the outputs, result is, far faster performance and zero impact to the underlying source. This object:
is the generally the cause of over 9 in 10 bottle-necks, slowdowns and server impacts yet is also one of the most easiest you can control. |

...
| Expand | |||||||
|---|---|---|---|---|---|---|---|
| |||||||
The ideal tool to slice and dice your data. They can be formed from dimensions, measures and calculations. They can use top n, bottom n, wildcard matching, type in and multi-select. Far more powerful (at least from a basic sense), than parameters, these filters really bring your visualisations to life. It's true, but these are amongst the biggest culprits for terrible data performance. Yet another one that fails to convey the impact to performance, you see, in order to build a quickfilterquick-filter, Tableau needs to run execute a Select Distinct on the entirety of the column, it matters not whether the table contains a thousand rows, or one-hundred trillion, it still needs to perform this. Net result, as many users routinely plug Tableau into tens and one-hundreds of millions of rows of data, do you have any idea how much processing just one quickfilter quick-filter takes to build. And then, the source-engine must start again for the next quickfilterquick-filter. So if your table contains 10M rows and you have just five quickfiltersquick-filters, the data engine must run this query once for each filter, touching every record in the set:
So essentially, the data engine will have touched 50 million records from a 10 million record set. Now do you understand? There are however, two type of filter that don't touch any records:
I can offer two further solutions that will enable yo to go crazy with your filters: (1.) Either use a parameter to filter your initial set or (2.) Have your filters on just a single page (1.) The quote I put at the top of this page regarding needing to re-build the r&d report, well, part of the problem was that this was plugged into a 2 billion row set with around 8 quickfilters quick filters that needed to be generated causing huge slow-downs on what was already a 650ms network lag. However, the r&d entries were all Jira tickets, and frustratingly, users were only interested in a single ticket id each time they were using the report, with the average data size per ticket being around 3 million rows. Ok, so part of the back-end rebuild I mentioned was to partition the data by ticket id which hugely improved performance but, from the front-end, simply converting the connection to CustomSQL with a type-in parameter for the where-clause (this was eventually populated over a url-call) resolved the problem.
Therefore, by using CustomSQL and a parameter to reduce your set to that which is of interest from the outset, your quickfilters quick-filters can be built against a much smaller set. (2.) The second alternative I can offer cam about from a pure accident: A second major drawback of the quickfilter quick-filter is that if the same filter is placed on more than one dashboard or chart page but, enough time passes between initially building the filters on page/dashboard 1, where other actions have taken place enough to clear the cache for the filters, when moving to the alternate pages, the quickfilters quick-filters must be re-generated with the same Select distinct query. I provided some consultancy to a company who just because they had 20 filters which took-up huge amounts of screen-space so, to save on space, we created a page of filters; it was awkward for the end-user to have to go back to the filters page when they wanted to adjust something, and I had to create an indicator to sit on every page to flag when and which filters were applied, but, the users were happy with it. Moreover, by moving the quickfilters quick-filters to the one page, this meant that despite their number, they would only have to query the data just once per session, which allowed for an improved experience. |
...
| Expand | ||
|---|---|---|
| ||
Unfortunately, development requests from another user can often cause this very important point to fall by the wayside. Dashboards need to be as clean as possible - the maxim Less is More is absolutely necessary here. Tools such as Excel and to a lessor degree, Powerpoint PowerPoint have enabled users to attempt to cram as much information as possible into the tiniest of spaces. Users have been brought-up on a diet of "All on one page". This is terrible, for a number of reasons:
Visuals (charts and tables) also need to be as clean as possible. The less ink on the page, the easier a chart is to read:
|
...