Tableau Best Practices
Its a sad fact of life but Tableau probably won't be around forever
Certainly as your company seeks out newer tools and data continues to grow exponentially
The problem is, your company knows this and has built, and continues to build systems in order to progress
It is very rare, and in most cases, improbable that your Tableau reports and analyses will consume data from a dedicated for-Tableau optimised data-warehouse, at best, you can hope that a warehouse for visualisation be made available, although most of the time, you will be consuming the same data as everyone else, such that unless you are a member of the BI team, or have ddl (Data Definition Language) access to the databases (required to create and optimise tables, views, etl etc), the chances are, you may not have a chance to optimise the back-end.
Best practice for performance is key to everything we do as Tableau developers; if our reports slow-down or, our reports create bottle-necks further down the chain, you can be guaranteed of the following (in this order):
- Users will tire of waiting, ultimately leading them to find alternatives for their answers
- Our reports may find themselves permanently disabled
- Who needs Tableau when we can write our own SQL and present in Excel? Sure, Tableau is prettier and makes it easier but those reports that slow everything down cannot be used
I actually experienced this myself several years ago: I was hired to fix the reports and improve their performance down from more than 5 minutes to do anything. Things had become so bad that the team had taken to Excel and had ditched the dedicated Tableau reports.
It took 2 months of investigation and re-building from scratch to fix the underlying problems in performance to achieve rendering times of under 10 seconds on a billion-row, 200-column mixed nvarchar / bigint table. Paid-off too as the report is still in use now (4 years later), which is great really given that this is the main R&D platform
I remember my Family Law lecturer when studying for my degree making the point that really, the subject should be called anti-family law as we spend more time trying to find the best approach to amicably break the family apart rather than creating one and/or keeping it together.
Using Tableau is no different: In order to ensure we as developers are getting the best from Tableau, we really need to be asking "is this method the best way to achieve this" or "is Tableau the best tool for the job" or "do we actually need this" and finally "I'm sure we can demonstrate this more simply than that"
Data drives everything.
Including your reports, but data is not always optimised for the job in-hand, and is often unable to be, so really you should see data and data performance as the main drivers behind your reports, don't try and over-wrangle Tableau.
So this where the following guide steps in, and a little more information can be found on the following pages:
Finally, this is my list of items to consider for best practice for all of your analyses and dashboards:
(1.) Only use calculations when you need them:
But calculations are Tableau's bread-and-butter aren't they? What can I possibly do if I cannot write calculations?
... you will need to create calculations in order for you to provide your analyses however, there are right ways and wrong ways to create calculations with the wrong ways having a detrimental effect to the back-end; however, only through the of the performance recorder will you know for sure the true impacts that you calculations are having.
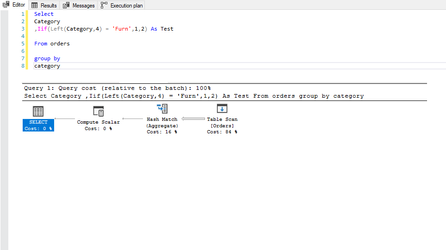
Classically, consider this calculation:
Iif(Left(Category,4) = 'Furn','1','2')
This is the query and execution plan from SQL Server:
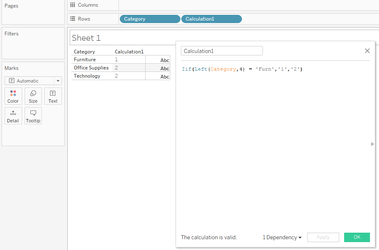
And now in Tableau:
| And now in Tableau | How Tableau has decided to interpret the calculation | And the plan of this new expression |
|---|---|---|
 |
|
|
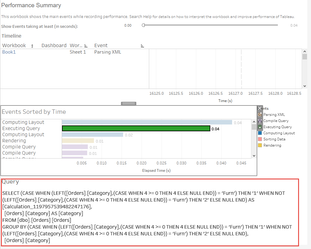
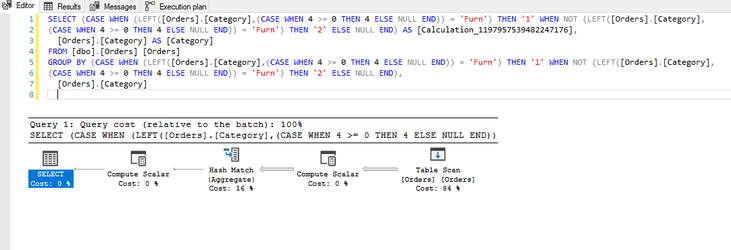
Notice the additional operation in the plan?
In this instance, this has resulted in a minimal change on a 9994 row set, but can you imagine the impact this could have on a million / billion or even trillion row set? Moreover, this example uses a table with no performance enhancements which has resulted in a full table scan and hash-match in both queries but crucially, if the table was indexed, the first query would likely be able to use the index to reduce the number of rows to be processed whereas the resultant query Tableau has produced, would mean the index would discarded and a full table scan would be required.
Moral of the story, yes, calculations are needed, you will be lost without them, but, just ensure the calculations you write perform to their best with minimal impact eg:
- Try to avoid huge nested case statements by getting to understand the relationship with the logic, this will allow the data-engine to quickly evaluate the statement regardless as to how Tableau re-writes your seemingly beautiful statement
- Utilise the RAW_ calculations wherever possible, these are designed to prevent Tableau from re-writing your query
- Create and test you calculations against the source to ensure they are optimally performant before moving them into Tableau
- Where possible, utilise external Python and R for complex calculations or when using a database, try to have complicated expressions built to the server a user-defined calculations to move some of the load from the main engine
- Only create the calculations you need
- And Never, be afraid to create multiple calculations that make slight alterations - Tableau will only use materialised calculations in its final query so try to avoid "one-size fit's all calculations"
(2.) Wherever possible ALWAYS use CustomSQL
Hold on a moment, the majority of the articles available online and other Tableau users generally advise to avoid CustomSQL and utilise the Tableau data-model, but you are telling me the exact reverse - why?
... that you will benefit from the best experience.
See my article Lets Talk: Custom SQL an in-depth explanation but CustomSQL offers the best performance: As an SQL analyst, you have the tools to be able to write much more performant code, and to test this code and where necessary, gain advice from others about how best to tune the query whereas, simply dragging and dropping the table objects and relying on Tableau to process the fields and connections, means that no-one will be able to optimise the code.
Also, most BI teams make data available through the use of optimised view's rather than direct access to the table so when Tableau executes its connection such as:
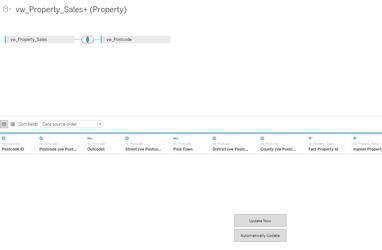
The query that Tableau is sending to the database engine will be a variation of:
Select vw_Property_Sales.* ,vw_Postcode.* From vw_Property_Sales Join vw_Postcode On vw_Property_Sales.Postcode = vw_Postcode.Postcode
this view for example:
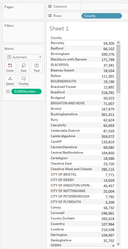
will generate a query similar to:
Select vw_Property_Sales.County ,Sum(1) As [Number of Records] From vw_Property_Sales Join vw_Postcode On vw_Property_Sales.Postcode = vw_Postcode.Postcode Group By vw_Property_Sales.County
But, where view's are used as is the case here, the actual query that needs to be processed by the database engine will actually look more like:
Which you can see is functionally identical to oft quoted reasons for NOT using CustomSQL.
However, two major points not covered which are generally the most important reasons for using CustomSQL:
- Notice that although Tableau is selective as to what data it is requesting, the view unfortunately will need to return all the data and perform in-memory filtering to get to the required data as a view, is simply the result-set of a query
- You on the other hand will be able to alter the selection in your query to get only the data you need to satisfy your requirements, even if this means creating multiple bespoke connections; keep in mind that a connection is nothing more than a semantic layer, and will only be made when the data is required from that connection.
- Parameterised queries: This neat little function allows for user selection driven data or rather, being able to write dynamic queries that change based on the selections of parameters, means you can create dynamic case statements, have a much selective where clause, filtering the source data before other filters are applied on the final result-set etc.
In short, CustomSQL allows you to harness the best from your database with the least amount of impact and to be able better control you data
(3.) Avoid nesting and materialise wherever possible
Ok, I think I understand this one, instead of writing nested queries, you suggest I should create separate calculations for what would be the nested calculations? Why, surely this will lead to more processing
(4.) Use Tableau built-in functions (aliases, groups, sets, bins etc) wherever possible instead of calculations or make the changes in CustomSQL
But calculations are easier and aliases / groups / bins etc may be single-use
... consider this calculation to alter the alias of Tenure Type : (running over a 30M row optimised set:
| Calc | Tableau Interpreted | Results in this plan |
|---|---|---|
Case [Tenure Type]
When 'F' Then 'Freehold'
When 'L' Then 'Leasehold'
Else 'Unknown'
End
| SELECT (CASE [vw_Property_Sales].[Tenure_Type] WHEN 'F' THEN 'Freehold' WHEN 'L' THEN 'Leasehold' ELSE 'Unknown' END) AS [Calculation_1483936116037431300] FROM [dbo].[vw_Property_Sales] [vw_Property_Sales] WHERE ([vw_Property_Sales].[Tenure_Type] = 'F') GROUP BY (CASE [vw_Property_Sales].[Tenure_Type] WHEN 'F' THEN 'Freehold' WHEN 'L' THEN 'Leasehold' ELSE 'Unknown' END) |
|

Where aliases, being a Tableau object result in no execution time in order to generate the outputs, result is, far faster performance and zero impact to the underlying source.
This object:
is the generally the cause of over 9 in 10 bottle-necks, slowdowns and server impacts yet is also one of the most easiest you can control.
(5.) Always test the performance using the performance recorder
About the Performance Recorder
The recorder simply records all Tableau events to help you identify performance issues.
The recorder is NOT a screen-capture device: it will not record screen activity, webcam or microphone and all recorded activity is saved locally.
(6.) Understand your use-case carefully and consider the best methods for connecting to your data
(7.) Additive Calculations belong in the source
(8.) Understand Tableau's role
(9.) Limit your use of filters
Are you kidding? If I don't have filters, my charts and dashboards will become unusable! It was only a matter of time before these ended-up on your list - killjoy!
(10.) Keep your visuals clean and your dashboards focused
(11.) Keep your work-space tidy
- Keep calculation and parameter names short, descriptive and where necessary, replace spaces with underscores:
- Default database behaviour is to surround all field names in square brackets, just in case there's a space in there. Sure, this isn't a problem, but when none of your fields contain spaces, you can do away withe the brackets in calculations, which improves readability (and helps with documentation too).
Remember to add comments in your calculations: Single-line comments follow two forward-strokes eg:
// This is a comment and will not be evaluated by Tableau (Sum(Sales) - Sum(Profit)) // * Sum(Profit) - Everything after the double forward-stroke is still a comment so shall not be evaluated
- Annotations (object comments) are really useful in understanding the purpose of a calculation or object (like a field, dimension or parameter etc) without needing to open it. Annotations use rich-text so you are free to format as you want. To add an annotation simply:
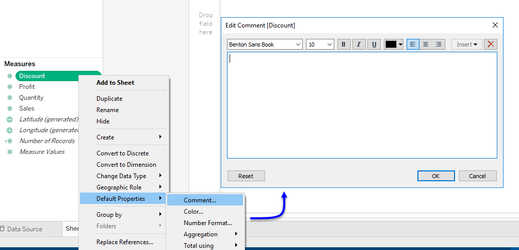
- Add your comments and press OK to save them
- Add your comments and press OK to save them
- Folders. Folders allow you to organise your work-space, however, you will need to alter the view model in order to access them which in so doing, will remove data-model groupings, so fields that are grouped by table from a joined data-model, will now lose their groupings to be listed alphabetically. No matter, if you want to add this arrangement back, simply create folders to represent the tables instead.
To switch to folders:- Select the menu option and alter to Group by Folder
- You will now be able to:
- Create new folders
- Delete existing folders
- Select a group of dimensions (or measures or parameters etc) and choose either to create a new folder (and insert into the folder) or to add to an existing folder
- Select the menu option and alter to Group by Folder